
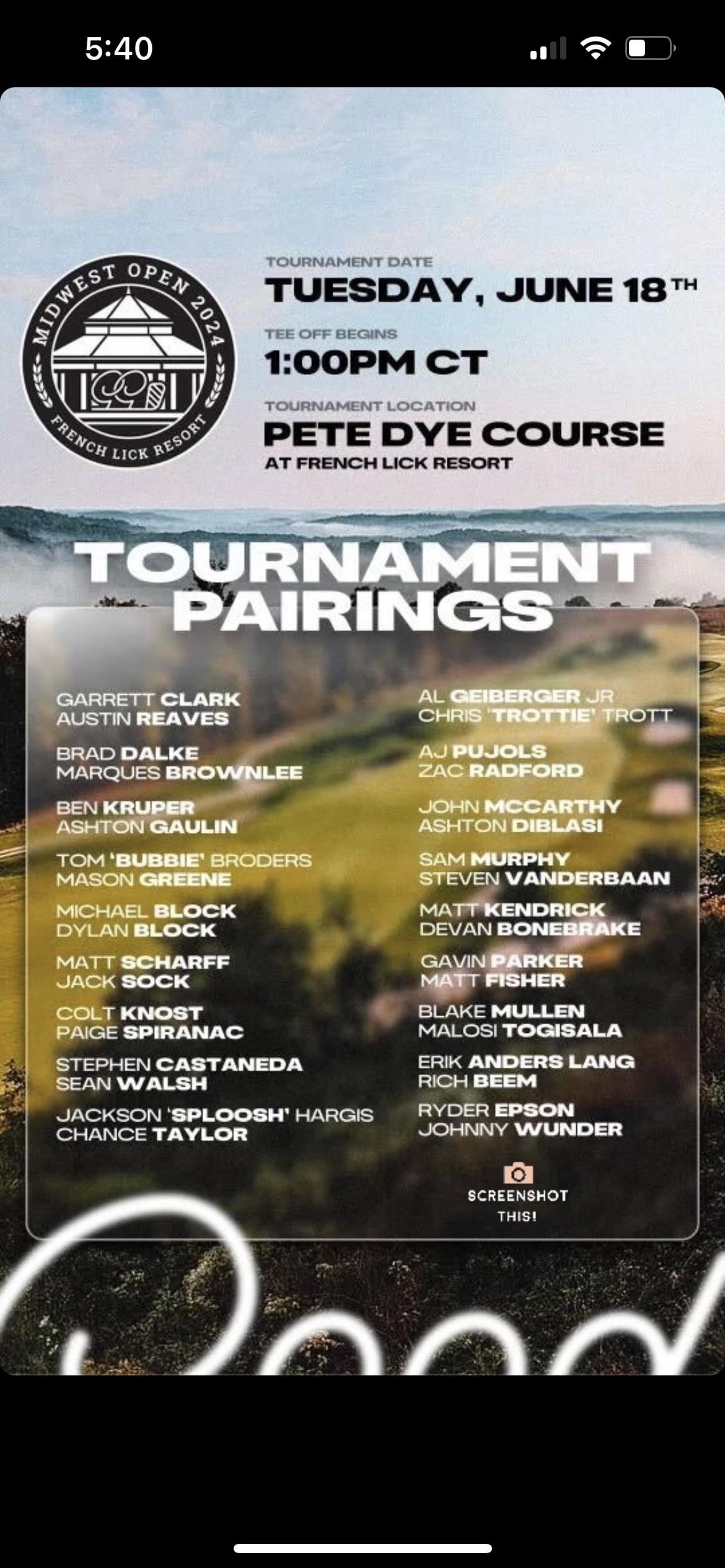
Alright folks, lemme tell ya ’bout my weekend dive into the “good good midwest open scores.” Saw some buzz about it online and figured, hey, why not try to wrangle some data and see what’s what.

First things first, I started by hitting up the official tournament site. Digging around, I was hoping for a nice, clean CSV file I could just slurp into a spreadsheet. No such luck! It was all embedded in some clunky HTML tables. Ugh.
Okay, time for plan B: web scraping. Now, I’m no expert, but I’ve dabbled before. Fired up Python and started cobbling together a script using BeautifulSoup. Man, that library is a lifesaver. It lets you parse the HTML and navigate the mess like a champ.
Spent a good hour figuring out the exact HTML structure, targeting the right tables, and extracting the data I needed: player names, scores, and rankings. Turns out, the HTML was kinda inconsistent, so I had to throw in some conditional logic to handle different table formats. Frustrating, but part of the game, right?
Once I had the raw data, it was a mess – strings, commas, weird characters everywhere. Time for some serious cleaning. Used a bunch of Python’s string manipulation functions to get everything into a usable format. Converted the scores to integers, handled missing values, the whole shebang.
Next, dumped the cleaned data into a Pandas DataFrame. Pandas is like Excel on steroids. Makes it super easy to analyze and manipulate tabular data. I grouped the scores by player and calculated averages, standard deviations, all that jazz. Wanted to see who was consistently performing well.

After that, I visualized the data using Matplotlib. Created some histograms to show the distribution of scores. Made a scatter plot to compare scores across different rounds. Visuals always help you understand the data better, you know?
Then I started digging into the specific players. Who had the best overall score? Who improved the most from round to round? Tried to identify any patterns or trends in the scores. It was kinda cool to see how the leaderboard shifted over the course of the tournament.
Finally, I saved all the processed data and visualizations to a local folder. Just in case I wanted to revisit it later or share it with someone. It’s always good to keep a record of your work.
All in all, it was a fun little project. Took me a few hours on a Sunday afternoon. Learned a bunch about web scraping, data cleaning, and analysis. And now I have a better understanding of the “good good midwest open scores” than I did before. Not bad, eh?
- Scraped the tournament website
- Cleaned and processed the raw data
- Analyzed the scores using Pandas
- Visualized the results with Matplotlib
Would I do it again? Sure! Data’s everywhere, and learning how to wrangle it is a valuable skill. Plus, it’s kinda satisfying to turn a mess of HTML into something useful and insightful.










{kind=link}