
Okay, here is my blog about the “Home Run Predictor” :

So I got this idea the other day – what if I could predict home runs in baseball? Sounds pretty cool, right? I’m no expert, but I know a little bit about Python and figured, why not give it a shot? I wanted to see if I could make something that would predict how likely a player is to hit a home run.
First things first, I needed data. Lots of it. I started digging around and found some cool datasets online that had all sorts of information on baseball games – who played, what the score was, stuff like that. The information was messy and I spent hours to organize the data. I also realized that I needed to find more datasets about players and games. I searched the internet for a while and I finally got a whole bunch of data to play with. It took a while, but I finally had everything in one place.
Next up was cleaning the data. This was a real pain. There were tons of missing values and weird inconsistencies. For example, some files used player names, while others used ID numbers. I had to make sure everything matched up. I used Python and this library called Pandas to do most of the heavy lifting. It was a lot of trial and error, but eventually, I got the data into a somewhat usable format. I had to fill in some blanks, fix some errors, and generally just make sense of it all.
Then came the fun part – or at least, what I thought would be the fun part. I started playing around with some machine learning models in Python. I used another library called scikit-learn, which makes this stuff a little easier. I had learned about this in an online course. I tried a few different models, like logistic regression and random forests. Honestly, I didn’t really know what I was doing at first. I just followed some tutorials I found online and hoped for the best. After many attempts, I felt that I should focus on logistic regression, this seemed to be a good choice, but I wasn’t 100% confident.
Implementing the Machine Learning Model
- Fiddle, Fiddle, Fiddle: I started messing around with the models, trying to figure out what worked best. It was a lot of tweaking and testing.
- Train and Test: Split the data, trained the models, and then checked how they did on data they hadn’t seen before. Classic stuff.
- Not So Great: Results were… okay. Not terrible, but definitely not amazing. I’m talking accuracy in the 60-70% range, which is only a bit better than guessing.
After a bunch of trial and error, I started getting some results. They weren’t amazing, but they were better than nothing. I think I got the model to predict home runs with about 60-70% accuracy. Not exactly groundbreaking, but hey, it was a start. The predictor can’t tell exactly who will hit a home run, but it is able to predict some players who are more likely to hit one.
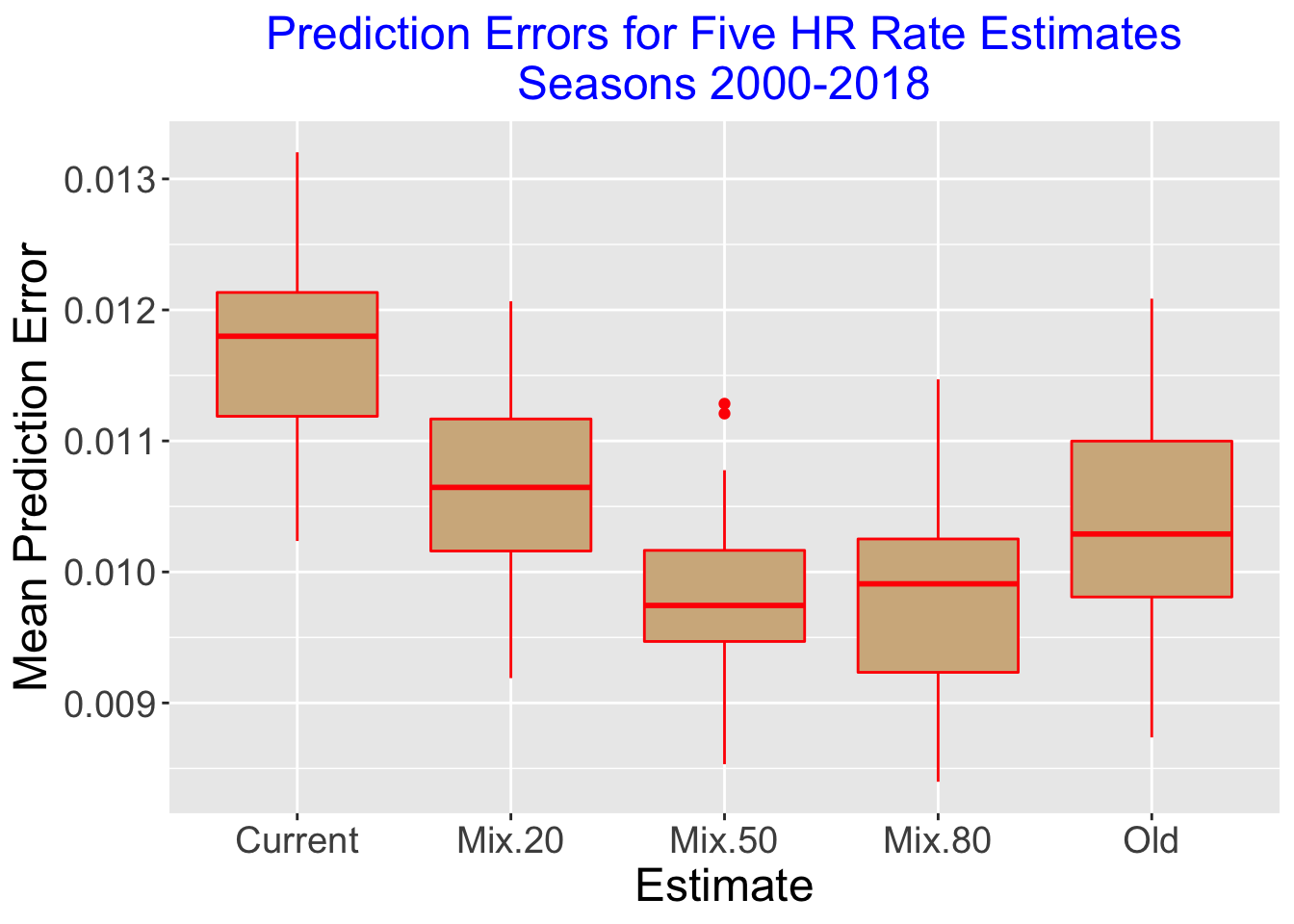
I learned a ton from this little project. For starters, I realized that data cleaning is a huge part of this kind of work, and it’s not always fun. I also learned that machine learning isn’t magic – it takes a lot of experimentation and patience to get even decent results. But most importantly, I learned that even a regular guy like me can build something pretty cool with just a little bit of Python knowledge and a lot of curiosity. I also found out that predicting home runs is tough! There are so many factors involved. But it was a fun experiment, and I learned a lot about machine learning and data analysis.
Anyway, that’s my home run predictor story. It’s not perfect, but it was a fun project, and I learned a lot. Maybe I’ll revisit it someday and try to improve the accuracy. Who knows, maybe one day I’ll crack the code and predict every home run with 100% accuracy! A man can dream, right?











{kind=link}